{kind=link}
Dette dokument giver en kort introduktion til de API‘er, der er tilgængelige på EnergyDataDK-platformen. Hvis du er ny på platformen, anbefaler vi at starte med Platformguiden og Dataejerguiden for at få et generelt overblik over Energydata.dk og dens funktioner.
Data kan importeres og eksporteres via et API, der findes følgende mekanismer:
Hvis du støder på fejl i dette dokument, eller har forbedringsforslag er du velkommen til at kontakte os på energydatadk@dtu.dk.
| Term | Meaning |
|---|---|
| API (Application Programming Interface) | A set of rules that allows different software systems to communicate and exchange data with each other. |
| MQTT (Message Queuing Telemetry Transport) | Lightweight messaging protocol used to transmit data between devices through a central server called a broker. It follows a publish/subscribe model: devices publish data to specific topics, and other devices subscribe to those topics to receive the messages. |
| MQTT Prefix | A single alphanumeric string configured by data owner. This prefix is placed at the beginning of all MQTT topics associated with specific data set. It acts as a simple identifier that groups topics together and distinguishes them from those of other data sets. |
| MQTT Sufix (Topic) | A unique label for a datastream. The suffix is added after the MQTT prefix and forms the full topic used when publishing or requesting data for that datastream. |
| Token | A token is a unique string used to authenticate and authorize access to an API or data service. It identifies the requester and ensures that only permitted systems or users can insert or retrieve data. |
| Deploy Token | A deploy token is a credential that is explicitly permitted to perform certain operations on specific datasets. It is intended for use when deploying devices or other systems in the field. Because a deploy token has only limited, predefined permissions, any compromise of the device or system using it results in minimal exposure. You can link any of the licenses you have via group memberships to the token. |
| Personal Access Token | A personal access token is a credential that carries the same rights as the user account that issued it. It is intended for use on the issuing user’s own computer for local development and testing.
Warning: If compromised, a personal access token can be used to access everything available to the issuing user. |
Hvilket tager dig til siden vist nedunder.
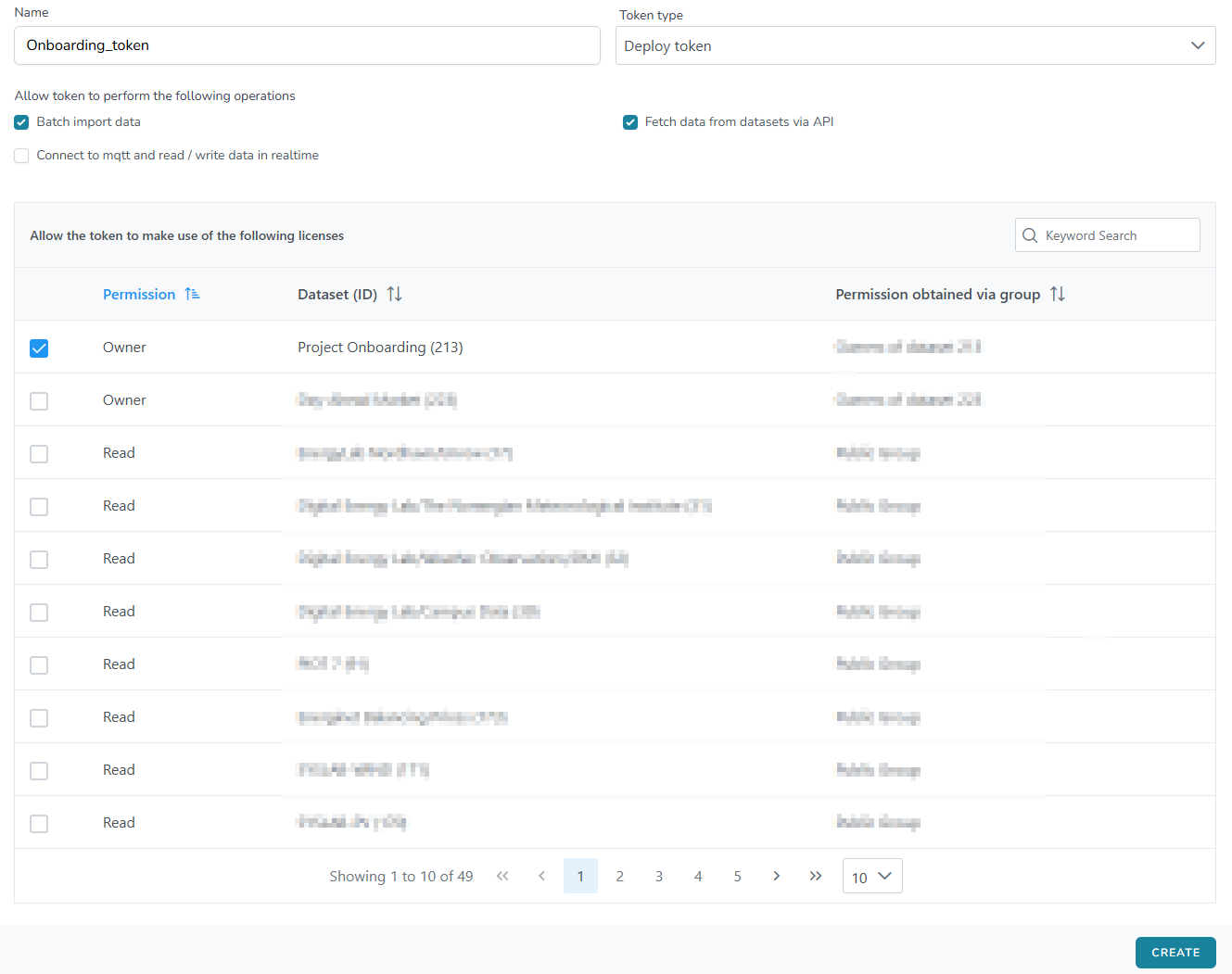
For at oprette et nyt token skal du indtaste et navn i feltet øverst, vælge tokentypen og derefter vælge tokentilladelserne. Der er to tokentyper tilgængelige: “Implementer token” og “Personlig adgangstoken”. Deres definitioner findes i afsnittet om terminologi i denne vejledning.
Token tilladelser
Tilladelserne som et specifik token kan tildeles er som følgende, flere valg er mulig:
For at selektere hvilket dataset du vil give tokenet adgang til, kan du bruge søgefeltet i nedre hjørnet til højre Figur 2.
Så snart alt er indstillet kan du oprette tokenet ved trykke på “Create” knappen ved bunden af siden. En pop up kommer op hvor API nøglen bliver vist. Vær meget opmærksom på, at nøglen bliver kun vist den ene gang, der vil ikke være muligheder at se det igen senere.
Administrer API tokens
Token administration er tilgængelig på samme side som hvor du opretter nye tokens.
Ved bunden af siden får du et overblik over alle tokens som er tidligere oprettet (Fig. 3).

Fra denne liste kan du se token detaljer, eller slette dem. Du vil dog ikke kunne se selve API nøglen.
Filen skal være formateret som CSV efter RFC4180 standarden. Ud over det, hvis filen indeholder ikke-ascii karakterer, bør filen blive kodet som UTF-8.
Den første række i CSV-filen skal indeholde overskrifter. Overskriften i en given kolonne identificerer den datastrøm, som kolonnens data skal importeres til. Overskriften kan enten være MQTT-emnet, der er knyttet til den givne datastrøm, for eksempel: “præfiks/suffiks”, eller datastrøms-ID’et, for eksempel: “123456”.
Den første kolonne i første række ignoreres.
Som dataejer tildeler du emner (topics) til datastrømme under datasæt oprettelsen. Hvis du har fået tildelt ejerrettigheder fra en anden bruger, eller du ikke har ejerrettigheder og du derfor ikke kender emnerne, kan du finde frem til emnet og datastrøm ID på flere måder. Disse metoder er beskrevet under
YYYY-MM-DD[T]HH:mm:ss.SSS[Z], f.eks. 2021-05-01T10:12:44.432Z for 1. maj 2023, 10:12:44.432 UTC. Tidsstemplet skal være i UTC-tidszonen. Nedenfor er en eksempelfil. Bemærk, at den første datastrøm (117217) er af typen streng, den anden datastrøm (my/topic) er af typen double, og den sidste datastrøm (119221) er af typen integer.
;117217;mit/emne;119221 2021-03-10T20:24:30.139Z;en_streng;23.4121;-10 2021-03-10T20:24:31.144Z;"endnu en streng";999888777.121;0 2021-03-10T20:24:32.161Z;en tredje streng;-1.33e-16;45 2021-03-10T20:24:33.186Z;;54.1;11 2021-03-10T20:24:34.201Z;en-fjerde-streng;;45
Læg mærke til at de tomme felter i række 5 (datastrøm 117217) og række 6 (my/topic). Til datastrøm 117217, bliver en tom streng importeret med tidsstempel 2021-03-10T20:24:33.186Z. Til datastrøm my/topic, vil ingen værdi blive importeret med timesstempel 2021-03-10T20:24:34.201Z.
EnergyDataDK’s API URL is: https://admin.energydata.dk/api/v1/import
Du kan gøre dette fra din computers terminal (kommandoprompt), og ordene i “<>” skal udfyldes med dine oplysninger.< og >.
Eksempel:
<username>@<domain>support@energydata.dk (Not <admin>@<domain>)Start din kommandolinjeterminal.
I Windows kan du gøre dette ved at trykke på + R, indtaste kommandoen “cmd” og trykke på “Enter”-tasten.
For at komme i gang skal du indtaste følgende kommando:
curl -H "Authorization: Bearer" -H "Accept: application/json" -X POST https://admin.energydata.dk/api/v1/import --data-urlencode "importname= "
Systemet returnerer et objekt med information om uploaden:
{
"user_id":<your_user_id>,
"status":"stored",
"name":"import_name",
"updated_at":"2025-09-17T08:15:43.000000Z",
"created_at":"2025-09-17T08:15:43.000000Z",
"id":00000
} Vi skal bruge id for at fortsætte med næste trin; at hente upload-URL‘en.
Brug id’et fra outputtet fra den forrige kommando til at indtaste følgende kommando:
curl -H "Authorization: Bearer" -H "Accept: application/json" "https://admin.energydata.dk/api/v1/import/ /upload_url"
Systemet returnerer dit unikke link, som vil se sådan ud:
{"upload_url":"https:\/\/s3.energydata.dk\/import\/inbox\/s123456\/a53f2b5d-0493-44ea-bed7-e48c26cf99ed.csv?X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=edk-s3-root%2F20250917%2Fdefault%2Fs3%2Faws4_request&X-Amz-Date=20250917T082537Z&X-Amz-SignedHeaders=host&X-Amz-Expires=7200&X-Amz-Signature=29744bc062fe06d545250c56b2cc8e19cdf4095b9fd936392fdb7f92ab88f1bc"} curl -H PUT -T "" -H "Content-Type: application/octet-stream" " "
Systemet returnerer ikke noget, men uploaden skal stadig valideres og indtages.
For at validere importen skal du indtaste følgende kommando:
curl -H "Authorization: Bearer" -H "Accept: application/json" -X PUT https://admin.energydata.dk/api/v1/import/<id>/validate
Systemet burde returnere noget lignende dette:
{
"id":00000,
"name":"import_name",
status":"validating",
"user_id":000,
"datastreams":null,
"validated_lines":0,
"ingested_lines":0,
"min_ts":null,
"max_ts":null,
"validated_at":null,
"ingested_at":null,
"created_at":"2026-04-08T11:06:52.000000Z",
"updated_at":"2026-04-08T11:35:05.000000Z"
} Det sidste trin er at indlæse uploaden. For at gøre dette skal du indtaste følgende kommando:
curl -H "Authorization: Bearer" -H "Accept: application/json" -X PUT https://admin.energydata.dk/api/v1/import/<id>/ingest
{
"id":00000,
"name":"Import_name",
"status":"ingesting",
"user_id":000,
"datastreams":[1000001,1000002,1000003],
"validated_lines":100,
"ingested_lines":0,
"min_ts":"2026-01-01T00:00:00.000000Z",
"max_ts":"2026-03-22T00:00:00.000000Z",
"validated_at":"2026-04-08T12:11:08.000000Z",
"ingested_at":null,
"created_at":"2026-04-08T12:09:50.000000Z",
"updated_at":"2026-04-08T12:13:21.000000Z"
} “Status” skal være “ingesting”. Hvis der er noget galt med din CSV-fil, får du i stedet følgende fejl:
{"error":"Unable to start ingestion"} Her er et eksempel på en Python-kode til batch-upload af data. Når du downloader, er det nødvendigt at ændre filen fra .txt til .py, eller blot kopiere og indsætte den i din foretrukne kodeeditor. Hvis du fortsætter med sidstnævnte, skal den opdeles i to filer med samme navne som de downloadede filer.
Hoved fil: batch_upload.py
Dette er den kode, der kræves for at uploade din csv-fil til EnergyDataDK. Du skal angive dit API-token og de datastrøms-ID’er, der svarer til de datastrømme, du vil uploade dine data til.
Det er ikke nødvendigt at ændre andet i koden udover de følgende 3 brugerdefinerede værdier.
<PATH_TO_YOUR_CSV_FILE>I Python kan du bruge “/”, “\\” eller “\\”. Da \U, \D osv. behandles som escape-sekvenser, anbefaler vi dog at bruge enten “/” eller “\\”, eller at tilføje “r” foran URL’en for at angive, at dette er en rå streng.<YOUR_FILE_NAME>: Indtast det midlertidige filnavn, der genereres under uploaden.<YOUR_TMP_DIR>: Indtast fil-stien til mappen, hvor den midlertidige fil skal gemmes under upload.python -m pip install pytz.
import pytz
import csv
from datetime import datetime
from EnergyDataImport import EnergyDataImport
# ###### CONFIGURATION ######
CSV_FILE_PATH = <PATH_TO_YOUR_CSV_FILE> # Format: r"C:\Users\You\Documents\data.csv"
AUTH_TOKEN = <YOUR_API_TOKEN> # Format: "12aBcd34e5FgH6IJklmNOpq7R8sTuvW9x0y1ZAbc"
DATASTREAM_IDS = <YOUR_DATASTREAMS_IDS> # Format: [1, 2...]
IMPORT_NAME = <YOUR_FILE_NAME> # Format: myFileName.csv
TMP_DIR = <YOUR_TMP_DIR> # Format: r"C:\Users\You\Documents\temporary"
# ###########################
# ----- NO NEED TO MODIFY ANYTHING AFTER THIS POINT -----
def run_multi_import():
# 1. Pass the list of IDs to the properties argument
with EnergyDataImport(
upload_filename=IMPORT_NAME,
properties=DATASTREAM_IDS, # Class creates a header with all IDs
energydata_api_token=AUTH_TOKEN,
overwrite=True,
tmp_dir=TMP_DIR
) as batch:
with open(CSV_FILE_PATH, mode='r', encoding='utf-8') as f:
reader = csv.reader(f, delimiter=';')
next(reader) # Skip metadata line
for row in reader:
if not row or len(row) < (len(DATASTREAM_IDS) + 1):
continue
# Parse timestamp (Column 0)
raw_ts = datetime.strptime(row[0], "%Y-%m-%dT%H:%M:%S.%fZ")
utc_ts = pytz.utc.localize(raw_ts)
# 2. Extract values for all streams (Columns 1, 2, and 3)
# Ensure the list length matches len(DATASTREAM_IDS)
values = [float(row[i+1]) for i in range(len(row)-1)]
# 3. Add the row to the batch
batch.add_values(utc_ts, values)
# Proceed with the standard lifecycle
batch.upload()
batch.validate()
batch.ingest()
if __name__ == "__main__":
run_multi_import()
Hjælpefil: EnergyDataImport.py
Denne kode indeholder funktionerne for hovedfejlen. Der kræves ingen ændringer.
import requests
import csv
import time
import os
import pytz
import json
from datetime import datetime
from enum import Enum
from typing import List
from pathlib import Path
class EnergyDataImport:
"""
A utility class to make batch importing to EnergyData.dk easier from Python.
This class handles building a CSV file in the correct format to be used for
importing to EnergyData.dk via the batch API. It manages the entire lifecycle:
creating the proper CSV, uploading, validating, and ingesting the file.
"""
# The API host for EnergyDataDK import endpoints
API_HOST = 'https://admin.energydata.dk/api/v1/import'
API_HEADERS = { 'Accept' : 'application/json' }
# The format required by EnergyDataDK for timestamps
TIMESTAMP_FORMAT = '%Y-%m-%dT%H:%M:%S.%fZ'
class Status(Enum):
"""Internal state machine to track the progress of the import job."""
UNINITIALIZED = 0
OPEN = 1
CLOSED = 2
UPLOADING = 3
STORED = 4
VALIDATING = 5
READY = 6
INGESTING = 7
DONE = 8
ABORTED = 9
ERROR = 10
def __init__(
self,
upload_filename: str,
properties: List,
energydata_api_token: str,
overwrite: bool = False,
tmp_dir: str = '/tmp/energydata_batch_upload',
autoclean_tmp_files: bool = True):
"""
Constructor for class. Create an instance for each batch upload.
An instance cannot be reused between multiple imports.
Args:
upload_filename (str): Name for the import file generated locally and used on the server.
properties (List): List of property IDs or Topics to which data will be added.
energydata_api_token (str): API token from https://portal.energydata.dk/user#accesstokens.
overwrite (bool): Controls whether to overwrite existing local or remote files.
tmp_dir (str): Directory for temporary CSV storage before upload.
autoclean_tmp_files (bool): If True, removes local files once the context is closed.
"""
self.status = self.Status.UNINITIALIZED
self.import_id = None
self.upload_url = None
self.added_lines = 0
self.previous_ts = None
self.upload_filename = upload_filename
self.local_file_path = Path.joinpath(Path(tmp_dir), Path(upload_filename))
self.properties = properties
self.energydata_api_token = energydata_api_token
self.overwrite = overwrite
self.tmp_dir = tmp_dir
self.autoclean_tmp_files = autoclean_tmp_files
self.api_headers = dict(self.API_HEADERS)
self.api_headers.update({'Authorization': f'Bearer {energydata_api_token}'})
def __enter__(self):
"""
Prepares the environment: creates the temp directory and opens the CSV file for writing.
"""
self.__assert_status(self.Status.UNINITIALIZED)
Path(self.tmp_dir).mkdir(parents=True, exist_ok=True)
if not self.overwrite and Path.exists(self.local_file_path):
raise Exception(f"File '{self.upload_filename}' already exists. Set overwrite=True.")
self.fd = open(self.local_file_path, mode='w', newline='')
# CSV format: delimiter ';', double quotes for strings, non-numeric quoting
self.writer = csv.writer(self.fd, quoting=csv.QUOTE_NONNUMERIC, delimiter=';',
quotechar='"', escapechar='\\', doublequote=False)
# Header row: First column is empty (reserved for timestamp), followed by property list
self.writer.writerow([''] + self.properties)
self.__change_status(self.Status.UNINITIALIZED, self.Status.OPEN)
return self
def __exit__(self, type, value, traceback):
"""Closes the file descriptor and handles automatic cleanup of local files."""
if hasattr(self, 'fd') and not self.fd.closed: self.fd.close()
if self.autoclean_tmp_files and os.path.exists(self.local_file_path):
os.remove(self.local_file_path)
self.status = self.Status.CLOSED
def add_values(self, time: datetime, values: List):
"""
Adds a row of data to the import buffer.
Args:
time (datetime): Timestamp. Must be timezone-aware.
values (List): Data values matching the number of properties in the constructor.
Raises:
Exception: If time is not timezone-aware or if timestamps are not monotonically increasing.
"""
self.__assert_status(self.Status.OPEN)
if time.tzinfo == None:
raise Exception("No timezone specified for the datetime object.")
if len(values) != len(self.properties):
raise Exception(f"Expected {len(self.properties)} values, found {len(values)}.")
if self.previous_ts is not None and time <= self.previous_ts:
raise Exception("Added timestamps must be strictly increasing.")
self.previous_ts = time
# Convert to UTC ISO format before writing
self.writer.writerow(
[time.astimezone(pytz.UTC).strftime(self.TIMESTAMP_FORMAT)] + list(values)
)
self.added_lines += 1
def upload(self, print_progress = True):
"""
Finalizes the CSV and uploads it to the server storage. Once called, state
transitions from OPEN to UPLOADING and finally to STORED.
"""
self.__change_status(self.Status.OPEN, self.Status.UPLOADING)
self.fd.close()
# 1. Create the import job record
res = requests.post(url=self.API_HOST, headers=self.api_headers, params={'importname': self.upload_filename})
res.raise_for_status()
self.import_id = res.json()['id']
# 2. Get the secure S3 upload URL
res = requests.get(url=f'{self.API_HOST}/{self.import_id}/upload_url', headers=self.api_headers)
res.raise_for_status()
self.upload_url = res.json()['upload_url'].replace("\\", "")
if print_progress: print(f'Starting file upload for job id: {self.import_id}')
# 3. Upload the binary data
with open(self.local_file_path, 'rb') as f:
res = requests.put(self.upload_url, data=f, headers={"Content-Type": "application/octet-stream"})
res.raise_for_status()
self.__change_status(self.Status.UPLOADING, self.Status.STORED)
if print_progress: print(f'Successfully stored job id {self.import_id}')
def validate(self, errors_limit = 0, block = True, print_progress = True):
"""
Triggers server-side validation. State transitions from STORED to VALIDATING
and finally to READY.
"""
self.__change_status(self.Status.STORED, self.Status.VALIDATING)
self.__api_put_request(block, 'validate', lambda s: self.__validation_progress(s, print_progress), {'errors_limit': errors_limit})
def ingest(self, block = True, print_progress = True):
"""
Triggers final ingestion. State transitions from READY to INGESTING
and finally to DONE.
"""
self.__change_status(self.Status.READY, self.Status.INGESTING)
self.__api_put_request(block, 'ingest', lambda s: self.__ingestion_progress(s, print_progress))
def __api_put_request(self, block, path, progress_callback, body = None):
"""Helper to send PUT requests and poll for status updates."""
res = requests.put(url=f'{self.API_HOST}/{self.import_id}/{path}', headers=self.api_headers, json=body)
res.raise_for_status()
while block:
time.sleep(5)
status = self.__get_status()
if not progress_callback(status): break
def __get_status(self):
"""Retrieves the current job metadata from the server."""
res = requests.get(url=f'{self.API_HOST}/{self.import_id}', headers=self.api_headers)
res.raise_for_status()
return res.json()
def __assert_status(self, expected):
if expected != self.status:
raise Exception(f"Expected status '{expected}', but found '{self.status}'")
def __change_status(self, expected, to):
self.__assert_status(expected)
self.status = to
def __validation_progress(self, status, print_progress):
if print_progress: print(f'Validated {status["validated_lines"]}/{self.added_lines} lines')
if status['status'] == 'validating': return True
if status['status'] == 'ready':
self.__change_status(self.Status.VALIDATING, self.Status.READY)
return False
raise Exception(f'Validation failed: {status["status"]}')
def __ingestion_progress(self, status, print_progress):
if print_progress: print(f'Ingested {status["ingested_lines"]}/{self.added_lines} lines')
if status['status'] == 'ingesting': return True
if status['status'] == 'done':
self.__change_status(self.Status.INGESTING, self.Status.DONE)
print("******Data uploaded successfully******")
return False
raise Exception(f'Ingestion failed: {status["status"]}')
Du kan anvende fetch data API‘et for at downloade data fra en aller adskillige datastrømme fra et datasæt. Vær opmærksom at du skal bruge læse-rettigheder for at kunne hente dataet. Ressourcen kan blive brugt til at hente de seneste værdier, eller værdier fra et tidsinterval.
Vær opmærksom på at denne ressource ikke returnerer JSON ved succesfulde forespørgsler. I disse tilfælde bliver respons data sent tilbage til klienten som CSV. Du bør dog stadig specificere “Accept: application/json” i headeren for at sikre at fejl bliver returneret til klienten som JSON.
For at hente data, skal du bruge følgende URL: https://admin.energydata.dk/api/v1/datastreams/values, med API parametre, som er:
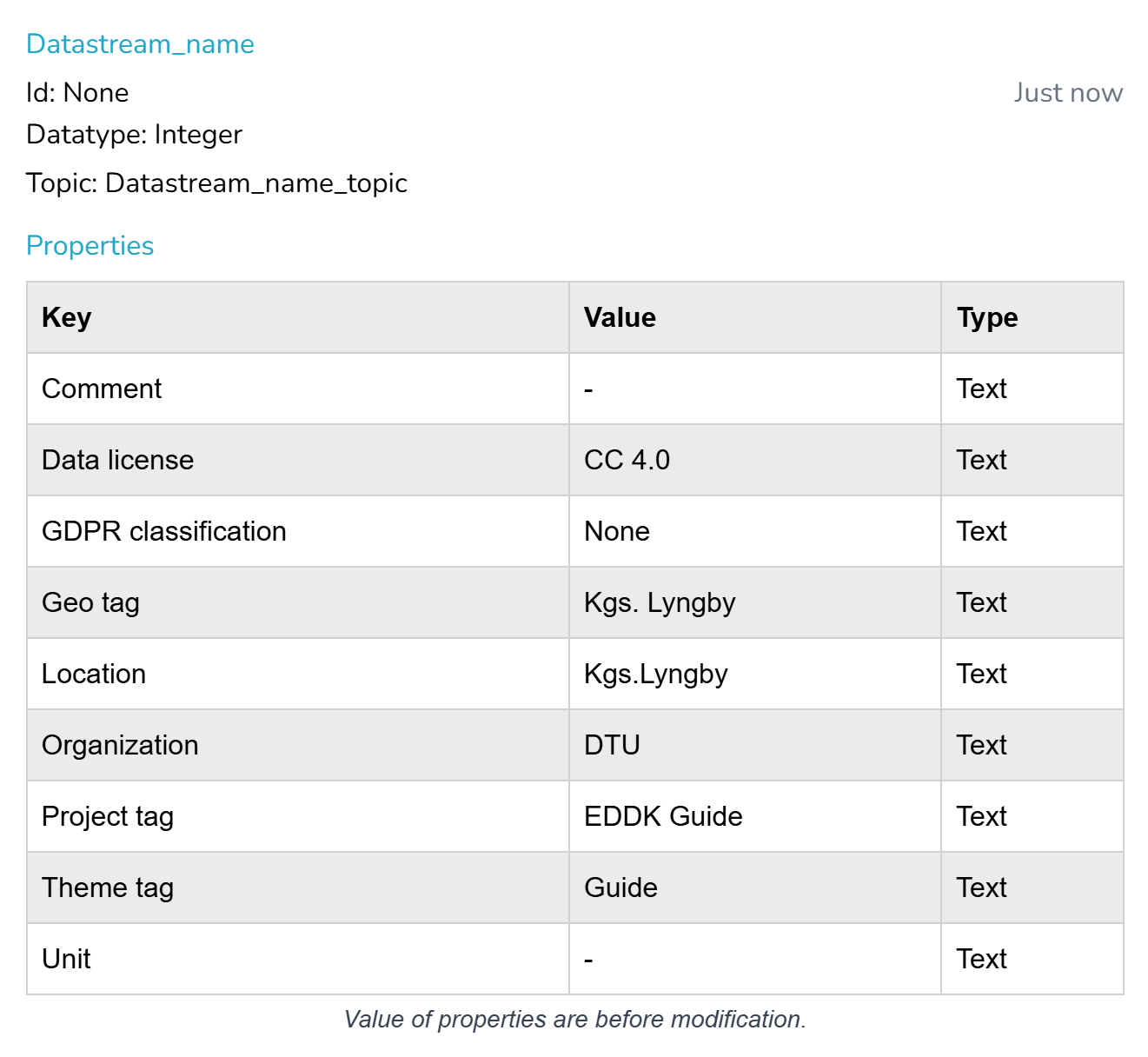
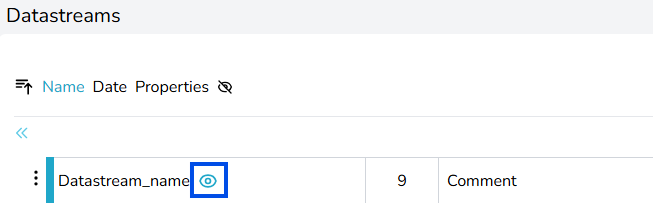
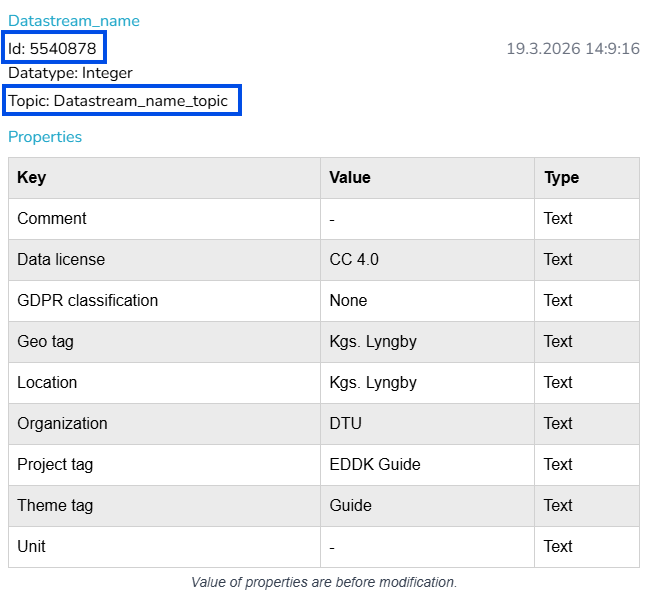
For at få adgang til datastrøms-id’erne, hvis du er ejeren, kan du se disse på den respektive datasætside ved at klikke på den datastrøm, du er interesseret i (se samme billede som i bad-uploaden). Hvis du kun har “Skrive”-rettigheder, kan du kun se disse selv ved at downloade en brøkdel af dataene fra webstedet, selvom de er tomme. Fra en sådan fil indeholder headerne de ønskede id’er og emner.
< og >.
Eksempel:
<username>@<domain>support@energydata.dk (Not <admin>@<domain>)curl -X GET "https://admin.energydata.dk/api/v1/datastreams/values?ids=&from= &to= " -H "Accept: application/json" -H "Authorization: Bearer " -o " "
For eksempel:
curl -X GET "https://admin.energydata.dk/api/v1/datastreams/values?ids=1001,1002,1003&from=1970-01-01&to=2030-12-31" -H "Accept: application/json" -H "Authorization: Bearer G7kPz2QmL9xVJ4aRfT8wNcY1sD3uHCoEb6Z5iX0A" -o "myOutputFile.csv"
Outputtet vil se nogenlunde sådan ud, men med de specifikke data fra din import. Output-CSV-filen vil blive gemt i den samme mappe, som du udstedte kommandoen fra.
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 46 0 46 0 0 271 0 --:--:-- --:--:-- --:--:-- 277
Denne metode returnerer den sidste række (eller tidsstempel) af den tilgængelige data for den specificerede datastrøm eller datastrømme. Du behøver ikke specificere “from” eller “to” kun datastrøm ID’et.
curl -X GET "https://admin.energydata.dk/api/v1/datastreams/values?ids=&latest=True" -H "Accept: application/json" -H "Authorization: Bearer " -o " "
For eksempel:
curl -X GET "https://admin.energydata.dk/api/v1/datastreams/values?ids=1001,1002,1003&latest=True" -H "Accept: application/json" -H "Authorization: Bearer G7kPz2QmL9xVJ4aRfT8wNcY1sD3uHCoEb6Z5iX0A" -o "myOutputFile.csv"
Outputtet vil se nogenlunde sådan ud, men med de specifikke data fra din import. Output-CSV-filen vil blive gemt i den samme mappe, som du udstedte kommandoen fra.
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 32 0 32 0 0 218 0 --:--:-- --:--:-- --:--:-- 225
MQTT API‘en giver dig mulighed for at uploade (publicere) data til en eller flere datastrømme eller downloade (abonnere på) en eller flere datastrømme i realtid. Flere værdier kan publiceres samtidigt, og MQTT‘s Quality of Service (QoS) understøttes.
For at bruge MQTT API‘en til at publicere eller abonnere på en datastrøm, skal du have et token, der giver rettigheder til at oprette forbindelse til MQTT-mægleren.
API‘et er bygget ovenpå MQTT protokollen, version 3.1.1. Mægleren er tilgængelig hos mqtts.energydata.dk og er åbn for MQTT forbindelser på port 8883.
Her er en oversigt over QoS-niveauerne:
Publicering af data giver dataudbydere mulighed for at sende data til lagring i EnergyDataDK. Det er muligt at udgive meddelelser med én eller flere værdier.
Beskeder med enkelværdi indeholder et tidsstempel og en værdi. Datastrømmen, der er knyttet til beskeden, udledes af MQTT-emnet. Tidsstemplet skal være et heltal i Unix Epoch-format, det vil sige antallet af millisekunder siden 01-01-1970. Værditypen afhænger af, hvad der er angivet for den specifikke datastrøm, streng, double eller heltal.
{
"timestamp": <unix_timestamp>,
"value": <value>
}
For eksempel:
{
"timestamp": 1775727761141
"value": 14.47
}
Multiværdimeddelelser bruges i situationer, hvor du har brug for at udgive flere forskellige, men relaterede værdier. De vil blive tilføjet med samme tidsstempe,l til det samme datasæt, på datastrømsemner angivet som følger:
{
"timestamp": <unix_timestamp>
"value": {
"<datastream_topic>": <value>,
⋯
}
}
For eksempel:
{
"timestamp": 1775727761141
"value": {
"a-datastream-topic": 14.47,
"other-datastream-topic": 34,
"last-datastream-topic": "Hello world",
}
}
Et eksempel på Python-kode til publicering af meddelelser med flere værdier kan findes nedenfor, hvor pladsholdere (ordene i “<>”) skal erstattes med dine oplysninger.
Der er 4 oplysninger, du skal tilpasse:
| Variable | Format |
|---|---|
| CLIENT_ID | Unik identifikator uden mellemrum. For eksempel:
|
| TOPIC | I meddelelser med flere værdier er datasættets emne påkrævet, og datastrømmens emner vil være defineret i nyttelasten.
I beskeder med én værdi skal det fulde emne (både suffiks og præfiks) angives.
|
| TOKEN | Dit API-token, som giver skriveadgang til det pågældende datasæt. For eksempel:
|
| VALUE | Den/de værdier, der skal indtastes i datastrømmen/datastrømmene. {
<DATASTREAM_TOPIC>: <VALUE>
}For eksempel: {
"b325/electricity-consumption": 34.5678,
"b329/electricity-consumption": 234.567
}
|
Tidsstemplet tilføjes automatisk og vil være det tidspunkt, du kører dette script.
python -m pip install paho-mqtt.
import paho.mqtt.client as mqtt
import time
import json
# MQTT Configuration
BROKER = "mqtts.test.energydata.dk"
PORT = 8883
KEEPALIVE = 45
TOPIC = "<MQTT_TOPIC>"
CLIENT_ID = "<MY_UNIQUE_MQTT_CLIENT_ID>"
TOKEN = "<API_TOKEN>"
VALUE = <VALUE>
# Connection tracking flag
connected = False
# Callback when connected
def on_connect(client, userdata, flags, rc):
global connected
if rc == 0:
print("Connected to broker.")
connected = True
else:
print(f"Connection failed with code {rc}.")
# Callback when disconnected
def on_disconnect(client, userdata, rc):
global connected
print("Disconnected.")
connected = False
# Create client
client = mqtt.Client(client_id=CLIENT_ID)
client.username_pw_set(username=TOKEN)
client.tls_set()
# Attach callbacks
client.on_connect = on_connect
client.on_disconnect = on_disconnect
# Connect to the broker
client.connect(host=BROKER, port=PORT, keepalive=KEEPALIVE)
# Start background loop
client.loop_start()
# Wait for connection
message_printed = False
while not connected:
if not message_printed:
print("Waiting for connection...")
message_printed = True
time.sleep(.5)
# Send messages
try:
timestamp = int(time.time() * 1000)
payload = {
"timestamp": timestamp,
"value": VALUE
}
# Publish the message
result = client.publish(topic=TOPIC, qos=0, payload=json.dumps(payload))
# Check the result
if result[0] == 0:
print(f"Message published successfully.")
else:
print(f"Failed to publish message, result code: {result[0]}.")
except KeyboardInterrupt:
print("Stopping publisher...")
except Exception as e:
print(f"Exception: {e}")
finally:
client.loop_stop()
client.disconnect()
Når du publicerer til EnergyDataDK ved hjælp af MQTT, bør du bruge Quality of Service (QoS) 1 for at sikre, at meddelelser leveres. Dette er især vigtigt, hvis du publicerer med en høj kapacitet, da overbelastningsbeskyttelsesmekanismer kan kassere dine meddelelser. Hvorfor og hvordan beskrives detaljeret nedenfor.
Når EnergydataDK MQTT-mægleren modtager en publiceringsbesked fra din klient, føjes beskeden til en kø af indgående beskeder. Denne kø er pr. klient og kan indeholde op til 1000 beskeder. Beskeder i køen fjernes fra køen serielt på en FIFO-måde. Når MQTT-brokeren fjernes fra køen, kontrollerer den, at klienten er autoriseret til at udgive beskeder om det givne emne.
Hvis autorisationen lykkes, videresendes beskeden til lagring i EnergyDataDK og til alle klienter, der abonnerer på det pågældende emne. Hvis beskeden blev publiceret med QoS 1 eller 2, sender MQTT‑brokeren kvitteringen, efter at autorisationen er gennemført.
Hvis godkendelsen mislykkes, afbrydes klientens forbindelse med det samme, og alle beskeder i køen for indgående beskeder kasseres.
Hvis MQTT-brokeren ikke kan følge med klienten, vil køen for indgående beskeder med tiden blive fuld. Når køen er fuld, kasserer MQTT-brokeren alle beskeder, den modtager fra klienten.
Det betyder, at din client skal begrænse sig selv for at undgå at miste beskeder. Du gør dette ved at udgive dine beskeder med QoS 1. Din klient skal derefter vente på at modtage en bekræftelse fra brokeren, før der udgives flere beskeder. Dette kan gøres i Python med paho-mqtt <https://pypi.python.org/pypi/pahomqtt/> bibliotek med funktionen wait_for_publish.
Det giver abonnenter mulighed for at modtage realtidsbeskeder med de data, der er offentliggjort på EnergyDataDK. Et eksempel på Python-kode om, hvordan man abonnerer på en specifik datastrøm for at hente dens livedata, vises nedenfor, hvor ordene i ” igen” står. <>” skal udfyldes med dine oplysninger.
import paho.mqtt.client as mqtt
from datetime import datetime, timezone
# MQTT Configuration
broker_host = 'mqtts.energydata.dk'
broker_port = 8883
subscribe_topic = "<mqtt_prefix/datastream_topic>"
token = "<your_token>"
# Callback when the client connects to the broker
def on_connect(client, userdata, flags, rc):
code_responses = [
"",
"unacceptable protocol version",
"identifier rejected",
"Server unavailable",
"bad user name or password",
"not authorized"
]
if rc == 0:
print(f"Connection Accepted: Connected to {broker_host} successfully!")
client.subscribe(subscribe_topic, qos=1)
print(f"Subscribed to topic: {subscribe_topic}")
else:
print(f"Connection refused: {code_responses[rc]}")
# Callback when a message is received
def on_message(client, userdata, msg):
payload = msg.payload.decode()
print(f"[{datetime.now(timezone.utc)}] Received `{payload}` from `{msg.topic}`")
# Create and configure the MQTT client
client = mqtt.Client()
client.username_pw_set(token)
client.tls_set()
client.on_connect = on_connect
client.on_message = on_message
# Connect and keep alive
client.connect(broker_host, broker_port)
client.loop_forever()
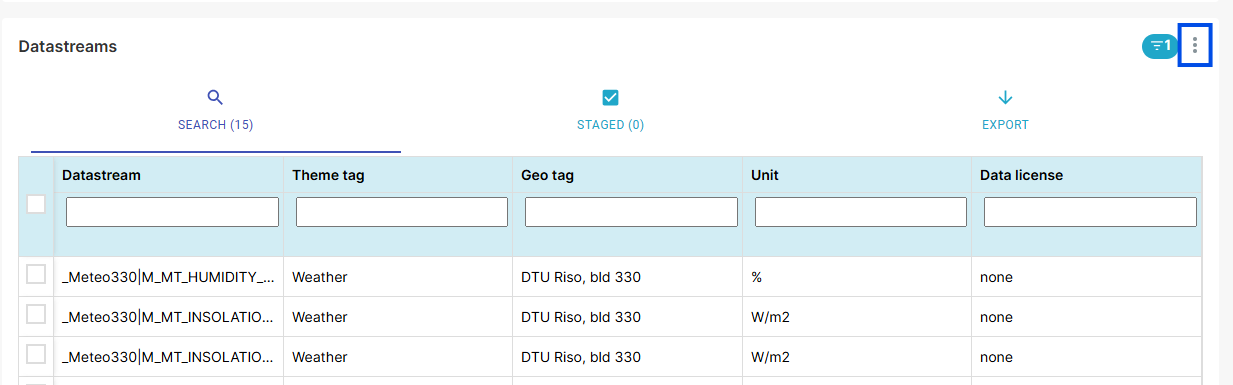
python -m pip install paho-mqtt.
En anden mulighed er at downloade de komplette metadata for det valgte datasæt ved at klikke på download-ikonet i øverste højre hjørne af Datastream-siden(fig. 5). Denne download indeholder metadata for alle datastrømme, samt deres respektive navne og ID’er.